
Gallery
Snapshots of my work in quantitative finance and data science
I develop rigorous statistical frameworks and machine learning systems to solve complex financial problems—from predictive modeling to risk analysis. Each project represents a full quantitative pipeline: data engineering, feature development, model selection, and actionable insights for financial decision-making.
By the numbers:
8+ statistical and ML modeling approaches deployed
70,000+ financial data points processed in largest analysis
95% average explanatory power across predictive models
4 financial domains: Risk, Sports Analytics, Climate Economics, Business Intelligence


Projects
Showcasing hands-on quantitative finance and data science work
Python • Pandas • REST API •Excel/VBA • Power BI
The Challenge
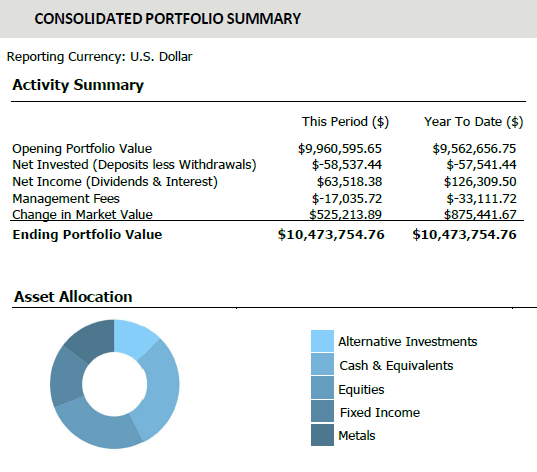
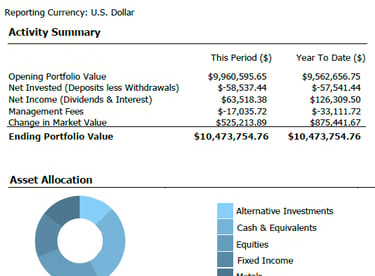
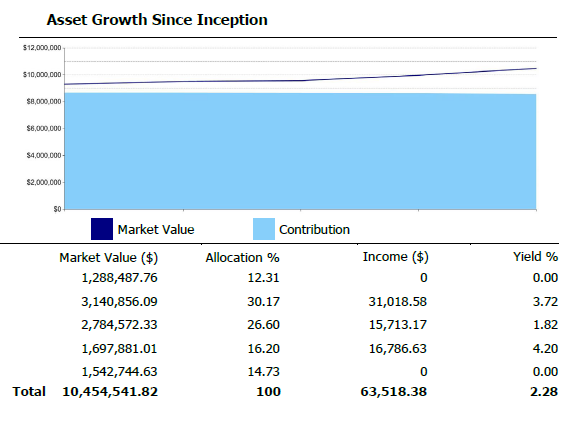
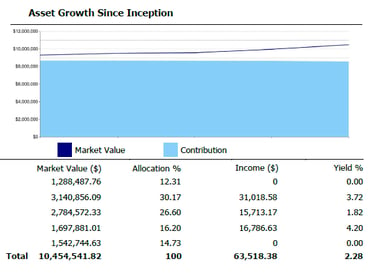
Manual data ingestion and reconciliation from IBKR Harmony consumed valuable analyst hours, creating bottlenecks in investment screening and portfolio reporting. The goal was to eliminate this manual workload to accelerate decision-making and improve data integrity.
My Approach
• Engineered a scalable Python pipeline that automated the entire data integration process
• Designed API-based ingestion to seamlessly process disparate data sources from IBKR/Harmony
• Developed dynamic Excel-based tools for market and options data analysis
• Created automated reporting systems for investor communications and attribution analysis
IBKR/Harmony Data -> Python Pipeline -> Excel/PowerBI Reports
Key Results:
• Reallocated 80% of analyst time from manual processing to quantitative strategy
• Dramatically increased operational efficiency and data reliability
• Accelerated portfolio construction through comparative quantitative models
• Enhanced accuracy of investment screening and strengthened client reporting
View Full Case Study (PDF) View Code on GitHub
Institutional Data Integration Engine
Engineering Automated Investment Workflows
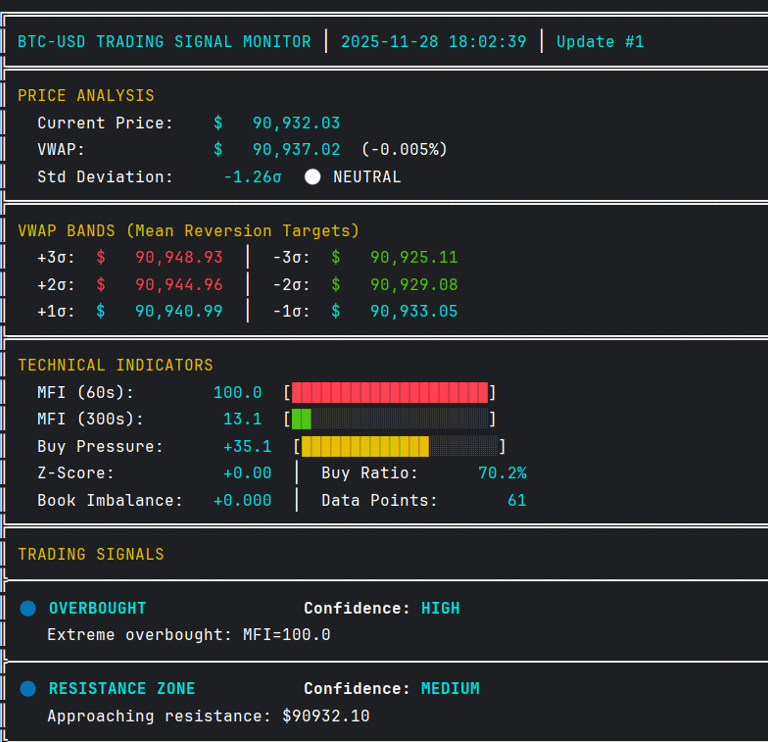
Quantitative Trading Deck
Institutional-grade systematic trading with sub-second latency.
Python • WebSockets • Asyncio • Quantitative Models
Market Microstructure
Coinbase WebSocket -> Data Pipeline -> Statistical Models -> Trading Alerts
The Objective
Cryptocurrency markets operate 24/7 with high volatility. The goal was to build a real-time quantitative trading system that processes Level 2 order book data, detects market microstructure signals, and identifies statistical mean reversion opportunities with institutional-level speed.
Technical Execution
• Architected a real-time monitoring system with direct WebSocket connectivity to Coinbase's institutional feed for sub-second latency
• Built an asynchronous Python engine using asyncio for parallel processing of order books, trades, and multi-timeframe technical indicators
• Developed proprietary models including VWAP standard deviation bands for mean reversion, a composite Buy Pressure Index combining order flow and momentum, and z-score anomaly detection
• Implemented market microstructure analytics to identify institutional order flow, detect spoofing behavior, and calculate real-time liquidity imbalances
WebSocket → Async Pipeline → Analysis → Signals Generation
The Resulting Advantage
The system achieves sub-second processing latency and generates trading signals based on multi-indicator confluence. It identifies mean reversion opportunities at 2-3σ from VWAP, detects institutional accumulation/distribution patterns, and provides real-time order book analysis—capabilities typically reserved for professional market makers and quant funds.


Institutional Trading Terminal
Full-stack trading platform with real-time execution and order book visualization.
The Problem
Bridging the Institutional Divide in Retail Trading
While retail trading platforms have democratized market access, they often lack the sophisticated tooling that institutional traders rely on for execution alpha. Most interfaces provide basic charting and order entry, but miss critical features like order book depth visualization, programmable hotkeys, and multi-symbol management—creating a structural disadvantage for retail participants.
Architecting the Solution
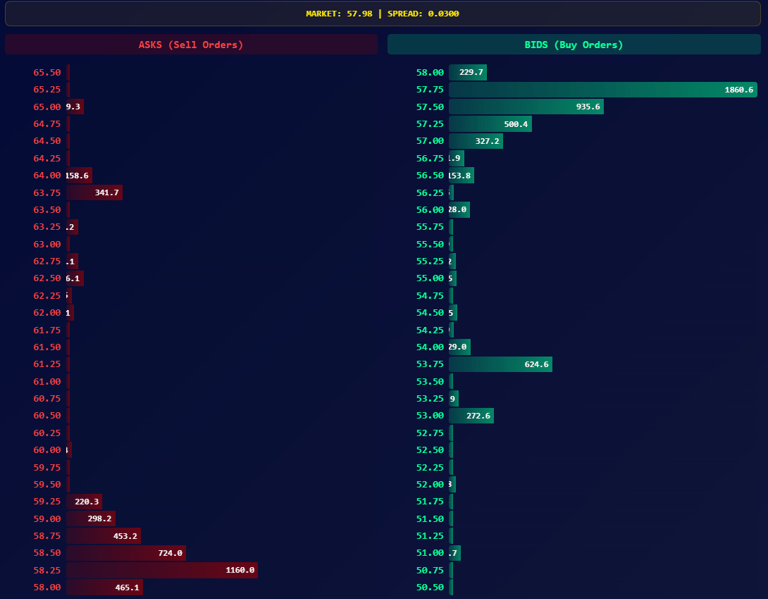
I engineered a full-stack trading platform from the ground up. The system features a robust Python backend with JWT authentication for secure API communication, a real-time order book depth visualizer, and an intuitive web interface with one-click trading and keyboard hotkeys. The platform supports multiple cryptocurrency pairs with post-only order execution at best bid/ask prices.
Cloud API -> Python Backend -> Web Interface -> Real-time Execution
Outcomes
Delivering Institutional Capabilities to Independent Traders
The terminal now provides retail traders with tools previously exclusive to professional desks: real-time order book visualization for market microstructure analysis, percentage-based scale orders for position management, and order chasing functionality for aggressive fills. This represents not just a technical achievement but a meaningful step toward leveling the playing field between institutional and retail market participants.
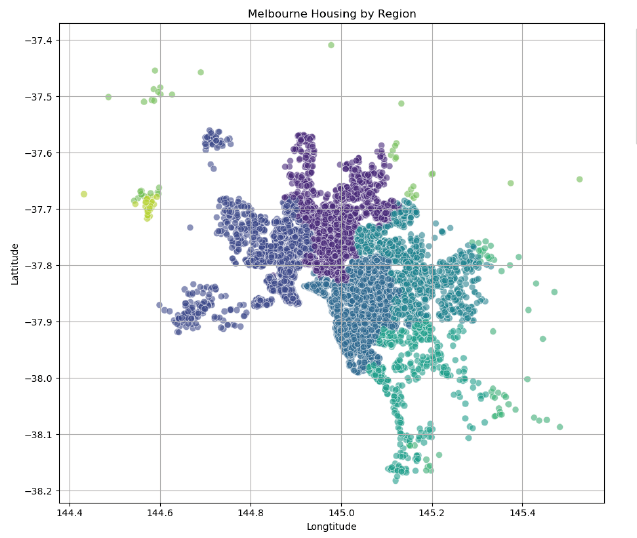
Predictive Modeling & Housing Price Intelligence Systematic comparison of machine learning models for real estate valuation.
Python • Scikit-learn • Pandas • Seaborn • Random Forest Feature Engineering
Objective
Out-predicting the real estate market
Real estate valuation requires understanding complex, multi-factor relationships. The goal was to systematically compare multiple machine learning approaches to predict Melbourne housing prices, identifying the most accurate and reliable methodology for property valuation.
The Approach
I conducted a comprehensive machine learning pipeline from exploratory data analysis to model deployment. This included rigorous data profiling, feature engineering (creating Price_per_Sqm and Property_Age), and systematic comparison of four regression models: Linear Regression, K-Nearest Neighbors, Decision Trees, and Random Forests using cross-validation and hyperparameter tuning.
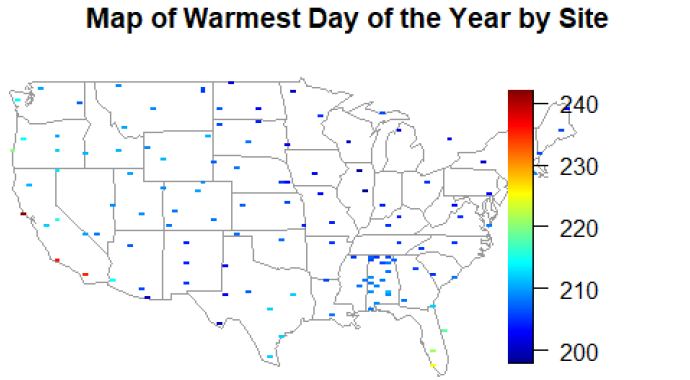
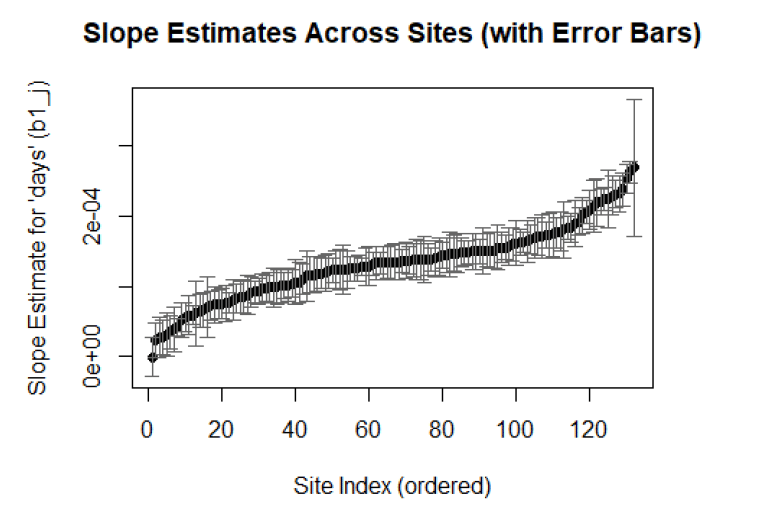
Climate Science & Statistical Modeling Spatial-temporal modeling of temperature patterns across 132 US climate stations
R • Linear Models • Lubridate Maps • Fields Fourier Analysis Spatial Statistics
The Challenge
Mapping America's Warming Climate
Understanding long-term climate trends requires analyzing complex temperature patterns across diverse geographic regions. The goal was to systematically model daily temperature variations across 132 US climate stations, identifying warming trends, seasonal patterns, and regional differences in temperature predictability.
The Analysis
Decoding the Signal from the Noise
I conducted a comprehensive spatial-temporal analysis using linear mixed effects modeling with Fourier components for seasonal variation. This included:
• Rigorous data cleaning and handling of missing values coded as -9999
• Creating seasonal covariates using sine/cosine terms
• Fitting separate models for each station to account for local climate patterns
• Estimating overall warming trends across all stations
The Result & Impact
The analysis revealed statistically significant warming trends across most US climate stations, with daily temperature increases up to 3.5×10⁻⁴°C/day (equivalent to 0.13°C/year). The models explained approximately 71% of temperature variation (R² = 0.712), with clear regional patterns in seasonal amplitude and residual variability identified through spatial mapping.
NFL Win Probability Forecasting
Advanced statistical modeling for predicting NFL team performance and game outcomes
R • GLM • Beta-Binomial Models • Mixed Effects Backward Elimination • Time Series
Mission
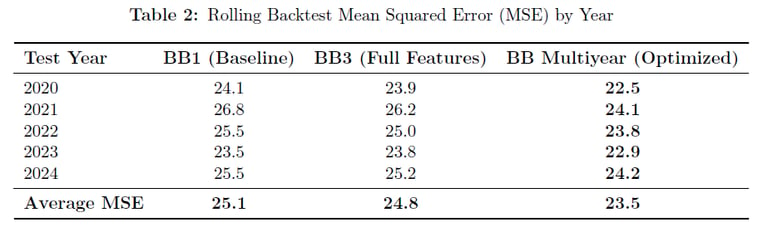
NFL team performance prediction requires accounting for complex factors including team efficiency, strength of schedule, and multiyear trends. The goal was to build a robust statistical framework to predict regular season wins for all 32 NFL teams and forecast individual game outcomes for the 2025 season.
Methodology
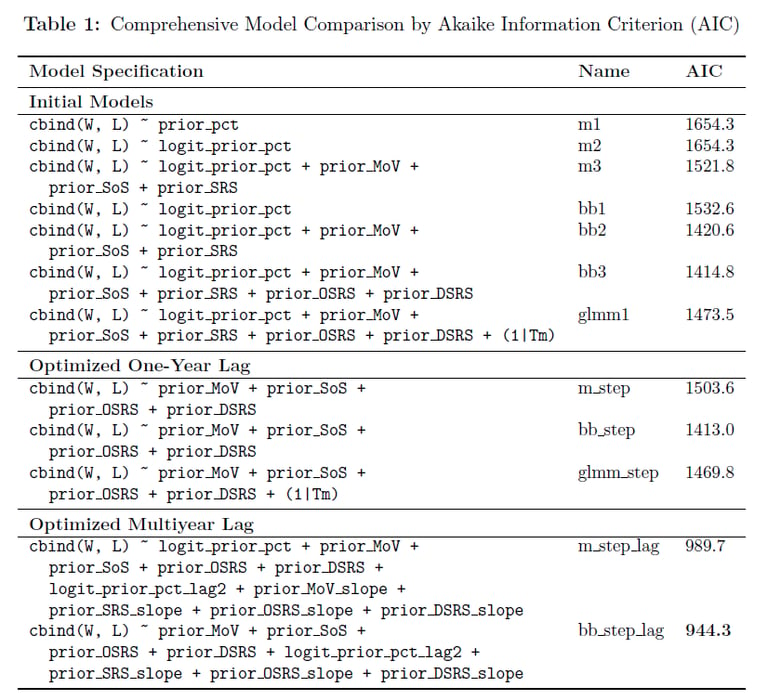
I developed and compared three primary modeling approaches: Binomial GLM, Beta-Binomial (accounting for overdispersion), and GLMM (with team random effects). Through rigorous backward elimination feature selection, I optimized models using one-year lag data and multiyear trends, incorporating performance slopes and efficiency metrics from the previous three seasons.
Performance
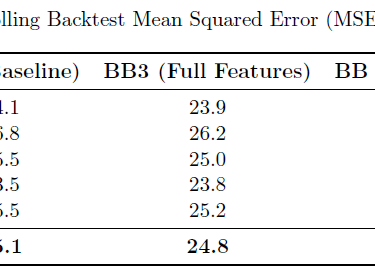
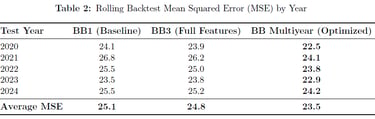
The optimized Beta-Binomial multiyear model achieved champion status with the lowest AIC (944.3) and superior out-of-sample performance (MSE 23.5). The model revealed that offensive/defensive efficiency metrics and multiyear trends are more predictive than simple win-loss records, projecting the Ravens (11.2 wins), 49ers (10.9), and Chiefs (10.7) as 2025 season leaders.
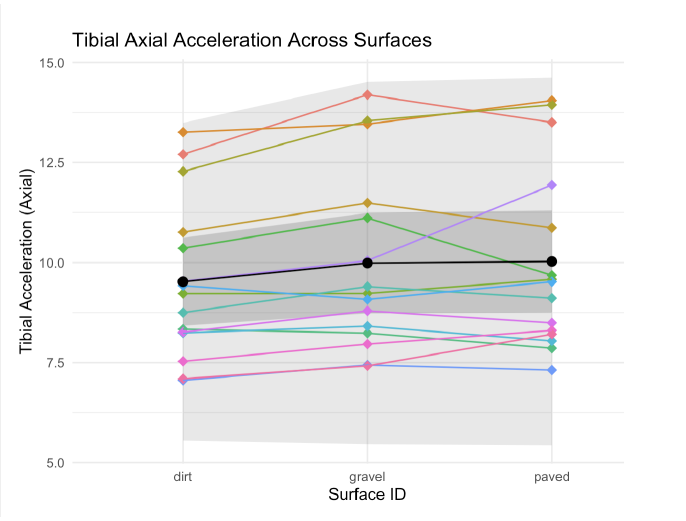
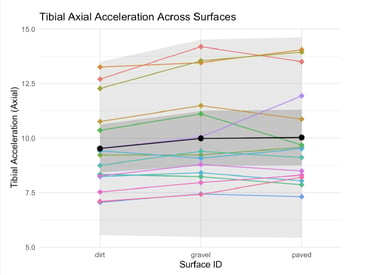
Running Surface Biomechanics Analysis
Mixed-effects modeling of tibial acceleration across different running surfaces
R • Linear Mixed Models • Repeated Measures • ANOVA • Test Corrections • Biomechanics
Goals & Scope
Running surface biomechanics research requires proper accounting for repeated measures and multiple comparisons. The goal was to replicate and re-analyze a published study on tibial accelerations across different running surfaces, applying robust statistical methods to address limitations in the original analysis.
Execution
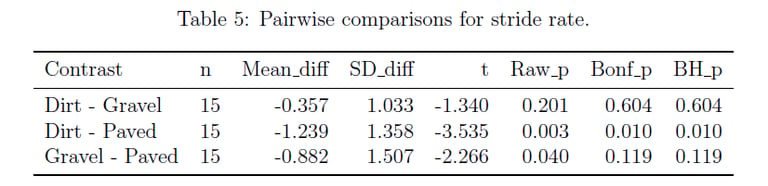
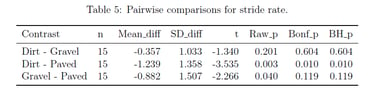
I implemented linear mixed-effects models with participant random effects to properly account for repeated measures design. I conducted comprehensive pairwise comparisons between dirt, gravel, and paved surfaces, applying both Bonferroni (familywise error rate control) and Benjamini-Hochberg (false discovery rate control) corrections for multiple testing.
Delivered Outcomes
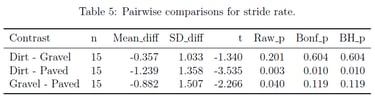
The analysis revealed significant reductions in tibial axial acceleration on dirt compared to gravel (p < 0.05 after both corrections), contradicting the original study's conclusions. The mixed-effects approach provided more accurate confidence intervals and revealed that the original study's statistical methodology had insufficient power to detect meaningful biomechanical differences.
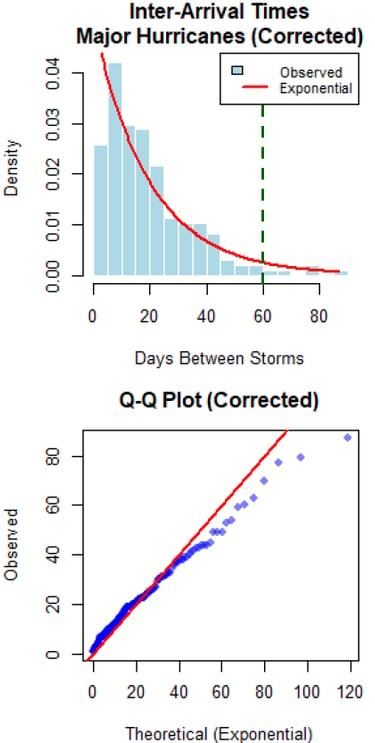
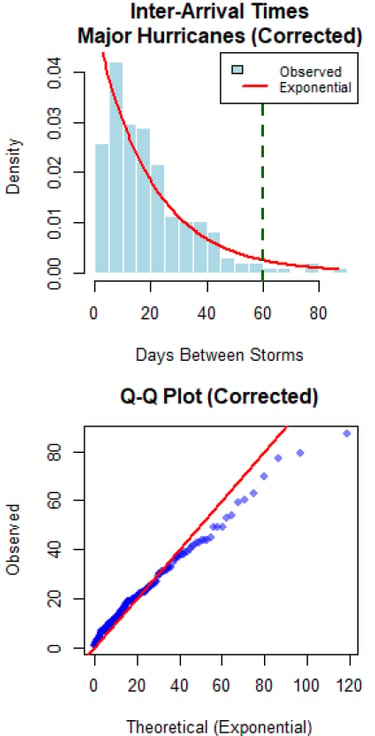
R • Statistical Testing • Exp. Distributions Spatial Analysis
Haversine Distance • Chi-Square Tests
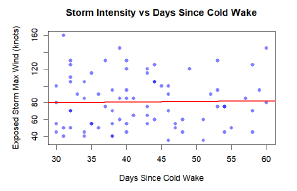
The Core Issue
Understanding tropical cyclone patterns is critical for disaster preparedness. The goal was to statistically test the "cold wake" hypothesis - whether major hurricanes create ocean cooling that suppresses subsequent storm formation - using historical hurricane data and rigorous statistical methodology.
Technical Response
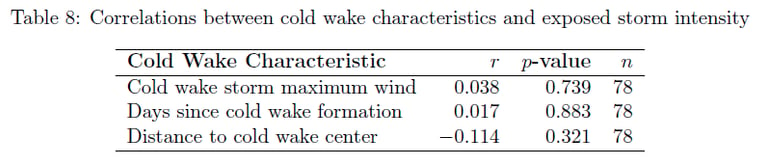
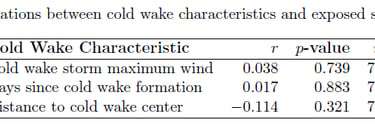
I conducted comprehensive inter-arrival time analysis using exponential distributions to test for temporal clustering/suppression. Developed spatial exposure criteria using Haversine distances to identify storms passing through cold wake regions, and performed statistical comparisons of storm intensities using Welch's t-tests and correlation analysis.
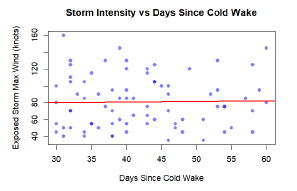
Results
The analysis found no evidence for cold wake suppression effects at the basin scale. Inter-arrival times followed exponential distributions (p > 0.05), and storms exposed to cold wakes showed no intensity reduction (exposed: 81.0 knots vs unexposed: 73.3 knots, p = 0.984). Results suggest climate oscillations dominate temporal patterns over localized ocean cooling effects.
Tropical Cyclone Cold Wake Analysis
Statistical testing of hurricane timing patterns and cold wake effects
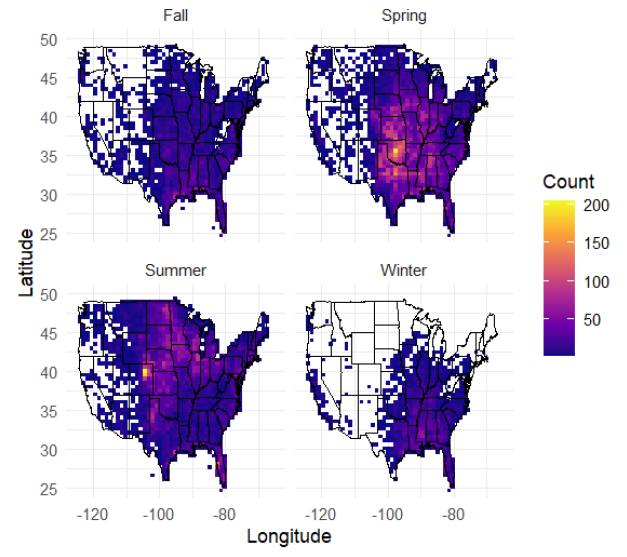
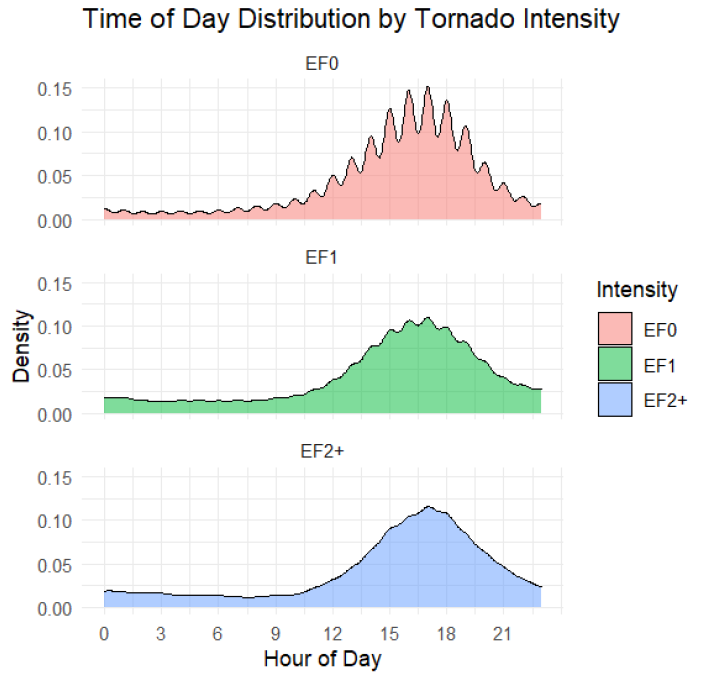
US Tornado Pattern Analysis
Comprehensive spatiotemporal analysis of 70,000+ tornado events across multiple dimensions
R • Spatial Statistics • GAM Models • Kernel Density Estimation Spatstat • Diurnal Cycle Analysis
Goal
Tornadoes represent one of the most destructive natural phenomena in the United States, yet their spatiotemporal patterns are not fully understood. The goal was to conduct a comprehensive analysis of 70,456 tornado events to identify long-term trends, seasonal migrations, diurnal cycles, and spatial distributions of tornado activity.
Proposed Solution
I employed multiple statistical approaches including Generalized Additive Models (GAMs) for trend analysis, kernel density estimation with great-circle distance metrics for spatial patterns, and temporal analysis of diurnal cycles. The analysis incorporated spatial point pattern analysis, multitype K-functions, and comprehensive visualization techniques across 74 years of tornado data.
Outcomes
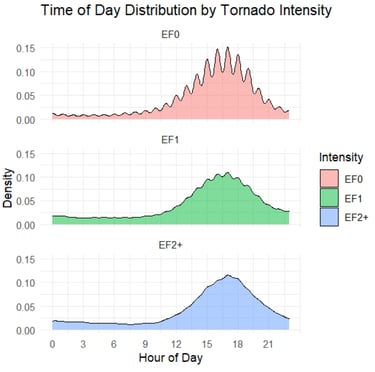
The analysis revealed systematic seasonal migration of tornado activity from Gulf Coast states in winter to Northern Plains in summer, with a pronounced diurnal peak at 5:00 PM (48% of tornadoes occur between 2-8 PM). Despite increased detection rates, tornado intensity distributions remained stable over time, and fatalities showed a significant downward trend due to improved warning systems.
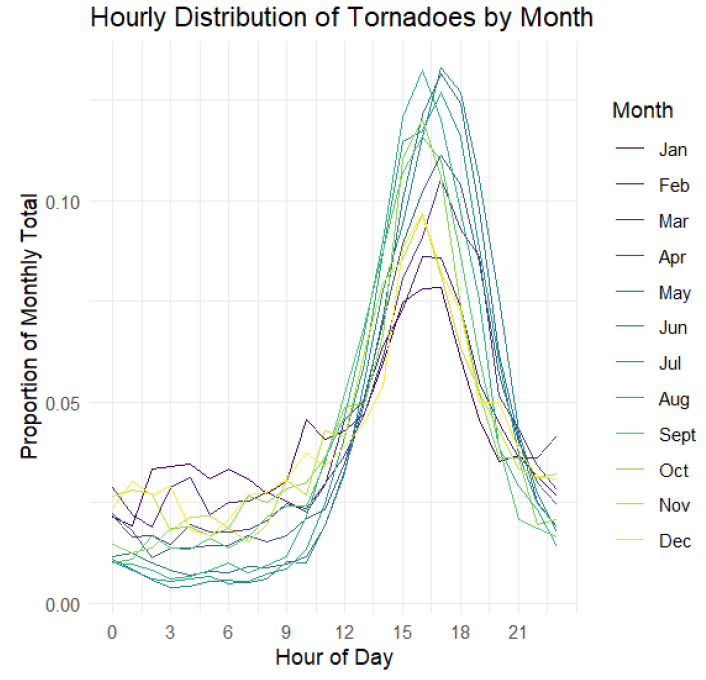
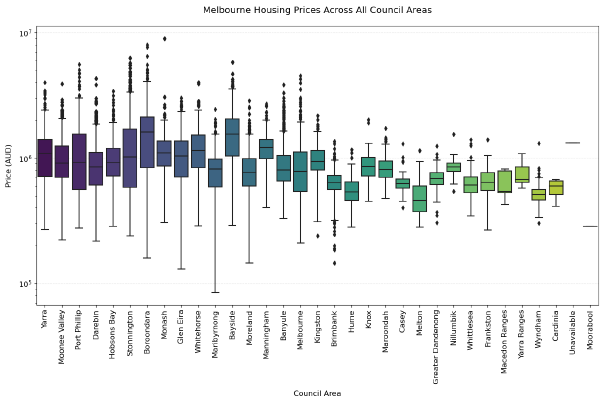
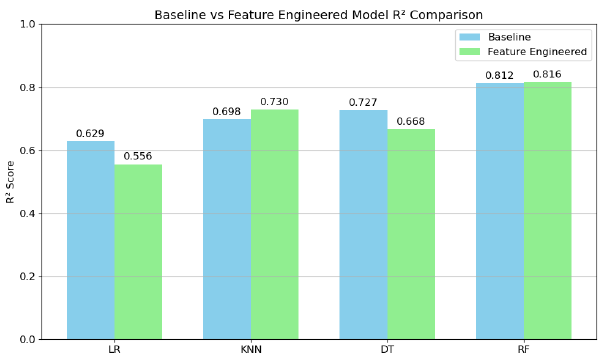
Results
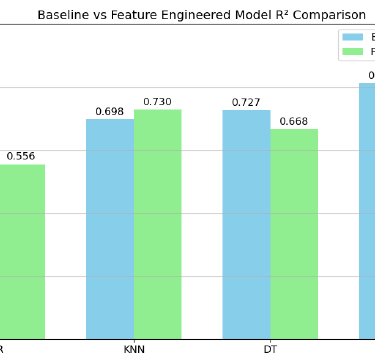
The Random Forest model achieved the best performance with an R² score of 0.816 and RMSE of $270,534 AUD, demonstrating strong predictive capability for housing prices. Feature engineering provided measurable improvements, with KNN showing the most significant gains (4.6% R² improvement) while maintaining robust model interpretability and validation.
Python • WebSockets • Asyncio • JWT Auth REST API • HTML/CSS/JS
Interested in talking markets, data, or building something new? I'm always happy to connect.
Python • WebSockets • Asyncio • Quantitative Models
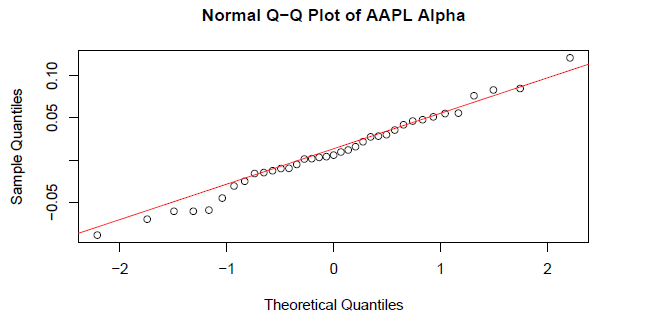
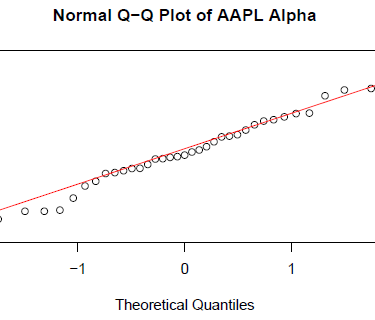
Market Microstructure Analysis & Anomaly Detection Earnings Data APIs → Pipeline → Statistical Models → Strategy Evaluation
Project Objective
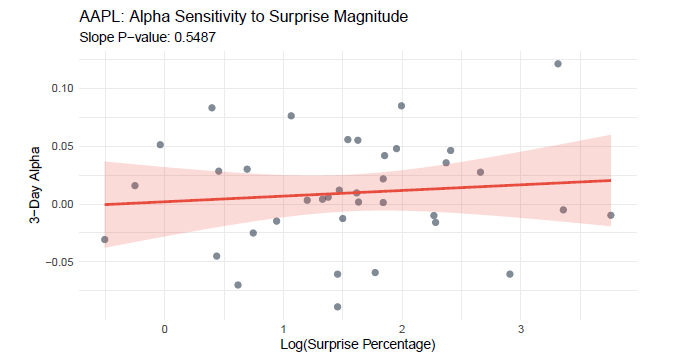
To empirically test the Post-Earnings Announcement Drift (PEAD) hypothesis by analyzing whether positive earnings surprises generate statistically significant excess returns (Alpha) in a 3-day window across 110 large-cap U.S. stocks.
Execution
• Built a systematic Python processing engine to clean, align, and compute 3-day Alpha for each earnings event, isolating stock-specific performance
• Implemented a statistical testing suite including normality assessment (Shapiro-Wilk), hypothesis testing (t-test, Wilcoxon), and correlation/regression analysis
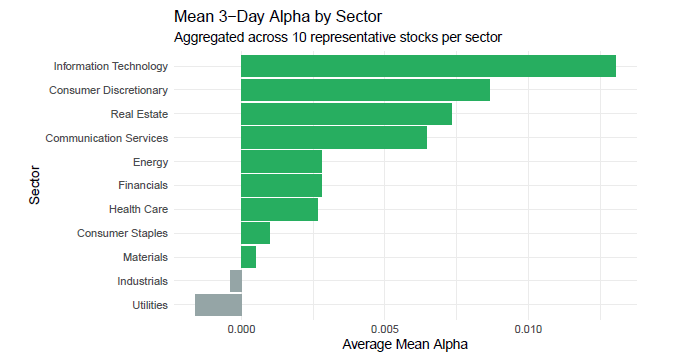
• Developed sector-level aggregation and visualization tools to examine cross-industry performance heterogeneity across 11 market sectors.
• Applied rigorous quality control checks to ensure temporal alignment, data completeness, and reproducibility across 1,100+ earnings events.
WebSocket → Async Pipeline → Analysis → Signals Generation
Insights
• Market Efficiency Validation: Only 10.9% of stocks exhibited statistically significant positive Alpha, supporting the Efficient Market Hypothesis for large-cap equities in short windows.
• Surprise-Insensitivity: Among outperformers, only 1 stock showed a significant relationship between surprise magnitude and Alpha, indicating weak predictive power
• Sectoral Patterns: Identified performance heterogeneity, with Technology and Real Estate showing higher mean Alpha, while Utilities and Industrials underperformed
• Actionable Conclusion: The findings challenge the profitability of a naive PEAD strategy for large-caps, highlighting the need for selective, sector-aware implementation or small-cap focus
Statistical Analysis of Short-Term Market Efficiency Following Positive Earnings Surprises
Testing the Post-Earnings Announcement Drift (PEAD) Hypothesis
Gallery
Snapshots of my work in quantitative finance and data science
I develop rigorous statistical frameworks and machine learning systems to solve complex financial problems—from predictive modeling to risk analysis. Each project represents a full quantitative pipeline: data engineering, feature development, model selection, and actionable insights for financial decision-making.
By the numbers:
8+ statistical and ML modeling approaches deployed
70,000+ financial data points processed in largest analysis
95% average explanatory power across predictive models
4 financial domains: Risk, Sports Analytics, Climate Economics, Business Intelligence
Projects
Showcasing hands-on quantitative finance and data science work
Python • Pandas • REST API •Excel/VBA Power BI
The Challenge
Manual data ingestion and reconciliation from IBKR Harmony consumed valuable analyst hours, creating bottlenecks in investment screening and portfolio reporting. The goal was to eliminate this manual workload to accelerate decision-making and improve data integrity.
My Approach
• Engineered a scalable Python pipeline that automated the entire data integration process
• Designed API-based ingestion to seamlessly process disparate data sources from IBKR/Harmony
• Developed dynamic Excel-based tools for market and options data analysis
• Created automated reporting systems for investor communications and attribution analysis
IBKR/Harmony Data -> Python Pipeline -> Excel/PowerBI Report Key Results:
• Reallocated 80% of analyst time from manual processing to quantitative strategy
• Dramatically increased operational efficiency and data reliability
• Accelerated portfolio construction through comparative quantitative models
• Enhanced accuracy of investment screening and strengthened client reporting
View Full Case Study (PDF) View Code on GitHub
Institutional Data Integration Engine
Engineering Automated Investment Workflows
Quantitative Trading Deck
Institutional-grade systematic trading with sub-second latency.
Python • WebSockets • Asyncio Quantitative Models • Market Microstructure
Coinbase WebSocket -> Data Pipeline -> Statistical Models -> Trading Alerts
The Objective
Cryptocurrency markets operate 24/7 with high volatility. The goal was to build a real-time quantitative trading system that processes Level 2 order book data, detects market microstructure signals, and identifies statistical mean reversion opportunities with institutional-level speed.
Technical Execution
• Architected a real-time monitoring system with direct WebSocket connectivity to Coinbase's institutional feed for sub-second latency
• Built an asynchronous Python engine using asyncio for parallel processing of order books, trades, and multi-timeframe technical indicators
• Developed proprietary models including VWAP standard deviation bands for mean reversion, a composite Buy Pressure Index combining order flow and momentum, and z-score anomaly detection
• Implemented market microstructure analytics to identify institutional order flow, detect spoofing behavior, and calculate real-time liquidity imbalances
The Resulting Advantage
The system achieves sub-second processing latency and generates trading signals based on multi-indicator confluence. It identifies mean reversion opportunities at 2-3σ from VWAP, detects institutional accumulation/distribution patterns, and provides real-time order book analysis—capabilities typically reserved for professional market makers and quant funds.
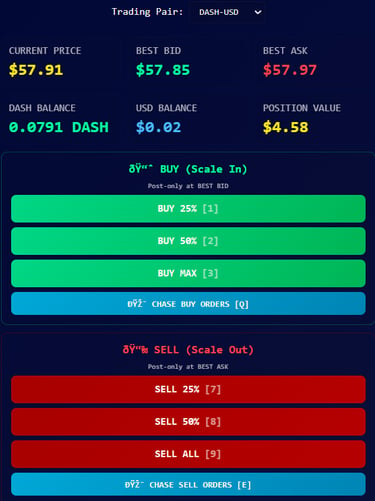
Institutional Trading Terminal
Full-stack trading platform with real-time execution and order book visualization.
The Problem
Bridging the Institutional Divide in Retail Trading
While retail trading platforms have democratized market access, they often lack the sophisticated tooling that institutional traders rely on for execution alpha. Most interfaces provide basic charting and order entry, but miss critical features like order book depth visualization, programmable hotkeys, and multi-symbol management—creating a structural disadvantage for retail participants.
Architecting the Solution
I engineered a full-stack trading platform from the ground up. The system features a robust Python backend with JWT authentication for secure API communication, a real-time order book depth visualizer, and an intuitive web interface with one-click trading and keyboard hotkeys. The platform supports multiple cryptocurrency pairs with post-only order execution at best bid/ask prices.
Cloud API -> Python Backend -> Web Interface -> Real-time Execution
Outcomes
Delivering Institutional Capabilities to Independent Traders
The terminal now provides retail traders with tools previously exclusive to professional desks: real-time order book visualization for market microstructure analysis, percentage-based scale orders for position management, and order chasing functionality for aggressive fills. This represents not just a technical achievement but a meaningful step toward leveling the playing field between institutional and retail market participants.
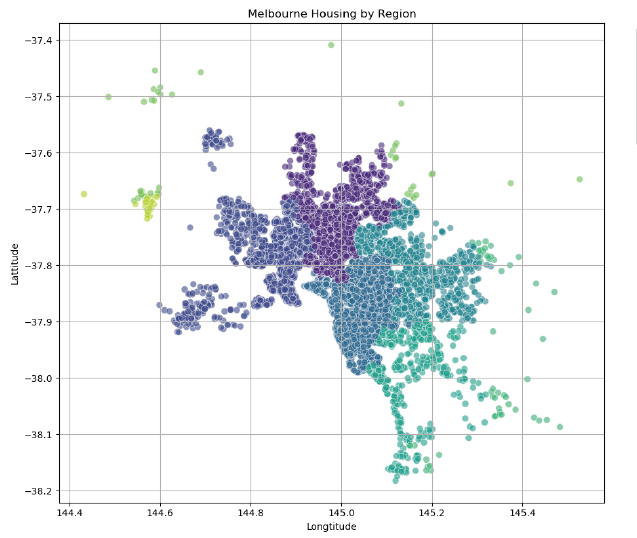
Predictive Modeling & Housing Price Intelligence Systematic comparison of machine learning models for real estate valuation.
Python • Scikit-learn • Pandas Seaborn • Random Forest Feature Engineering
Objective
Out-predicting the real estate market
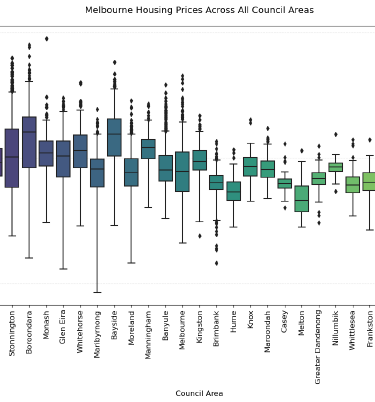
Real estate valuation requires understanding complex, multi-factor relationships. The goal was to systematically compare multiple machine learning approaches to predict Melbourne housing prices, identifying the most accurate and reliable methodology for property valuation.
The Approach
I conducted a comprehensive machine learning pipeline from exploratory data analysis to model deployment. This included rigorous data profiling, feature engineering (creating Price_per_Sqm and Property_Age), and systematic comparison of four regression models: Linear Regression, K-Nearest Neighbors, Decision Trees, and Random Forests using cross-validation and hyperparameter tuning.
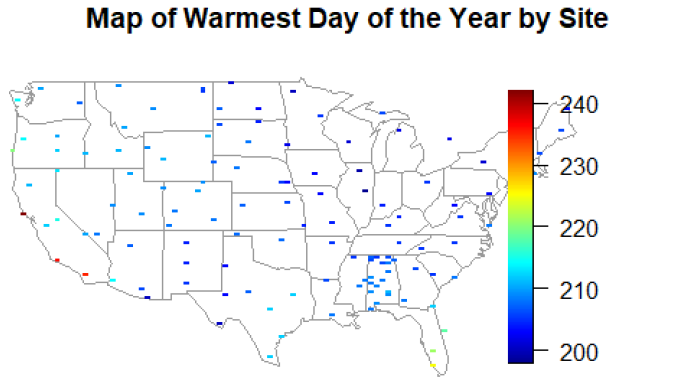
Climate Science & Statistical Modeling Spatial-temporal modeling of temperature patterns across 132 US climate stations
R • Linear Models • Lubridate Maps Fields Fourier Analysis • Spatial Statistics
The Challenge
Mapping America's Warming Climate
Understanding long-term climate trends requires analyzing complex temperature patterns across diverse geographic regions. The goal was to systematically model daily temperature variations across 132 US climate stations, identifying warming trends, seasonal patterns, and regional differences in temperature predictability.
The Analysis
Decoding the Signal from the Noise
I conducted a comprehensive spatial-temporal analysis using linear mixed effects modeling with Fourier components for seasonal variation. This included:
• Rigorous data cleaning and handling of missing values coded as -9999
• Creating seasonal covariates using sine/cosine terms
• Fitting separate models for each station to account for local climate patterns
• Estimating overall warming trends across all stations
The Result & Impact
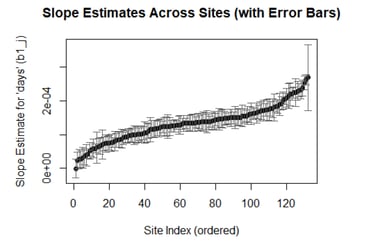
The analysis revealed statistically significant warming trends across most US climate stations, with daily temperature increases up to 3.5×10⁻⁴°C/day (equivalent to 0.13°C/year). The models explained approximately 71% of temperature variation (R² = 0.712), with clear regional patterns in seasonal amplitude and residual variability identified through spatial mapping.
NFL Win Probability Forecasting
Advanced statistical modeling for predicting NFL team performance and game outcomes
R • GLM • Beta-Binomial Models Mixed Effects • Backward Elimination Time Series
Mission
NFL team performance prediction requires accounting for complex factors including team efficiency, strength of schedule, and multiyear trends. The goal was to build a robust statistical framework to predict regular season wins for all 32 NFL teams and forecast individual game outcomes for the 2025 season.
Methodology
I developed and compared three primary modeling approaches: Binomial GLM, Beta-Binomial (accounting for overdispersion), and GLMM (with team random effects). Through rigorous backward elimination feature selection, I optimized models using one-year lag data and multiyear trends, incorporating performance slopes and efficiency metrics from the previous three seasons.
Performance
The optimized Beta-Binomial multiyear model achieved champion status with the lowest AIC (944.3) and superior out-of-sample performance (MSE 23.5). The model revealed that offensive/defensive efficiency metrics and multiyear trends are more predictive than simple win-loss records, projecting the Ravens (11.2 wins), 49ers (10.9), and Chiefs (10.7) as 2025 season leaders.
Running Surface Biomechanics Analysis
Mixed-effects modeling of tibial acceleration across different running surfaces
R • Linear Mixed Models Repeated Measures • ANOVA • Test Corrections • Biomechanics
Goals & Scope
Running surface biomechanics research requires proper accounting for repeated measures and multiple comparisons. The goal was to replicate and re-analyze a published study on tibial accelerations across different running surfaces, applying robust statistical methods to address limitations in the original analysis.
Execution
I implemented linear mixed-effects models with participant random effects to properly account for repeated measures design. I conducted comprehensive pairwise comparisons between dirt, gravel, and paved surfaces, applying both Bonferroni (familywise error rate control) and Benjamini-Hochberg (false discovery rate control) corrections for multiple testing.
Delivered Outcomes
The analysis revealed significant reductions in tibial axial acceleration on dirt compared to gravel (p < 0.05 after both corrections), contradicting the original study's conclusions. The mixed-effects approach provided more accurate confidence intervals and revealed that the original study's statistical methodology had insufficient power to detect meaningful biomechanical differences.
R • Statistical Testing • Exp. Distributions
Spatial Analysis
Haversine Distance • Chi-Square Tests
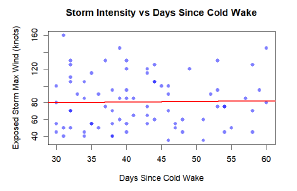
The Core Issue
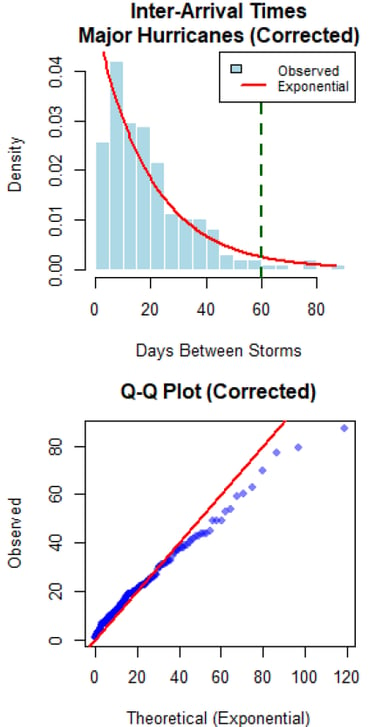
Understanding tropical cyclone patterns is critical for disaster preparedness. The goal was to statistically test the "cold wake" hypothesis - whether major hurricanes create ocean cooling that suppresses subsequent storm formation - using historical hurricane data and rigorous statistical methodology.
Technical Response
I conducted comprehensive inter-arrival time analysis using exponential distributions to test for temporal clustering/suppression. Developed spatial exposure criteria using Haversine distances to identify storms passing through cold wake regions, and performed statistical comparisons of storm intensities using Welch's t-tests and correlation analysis.
Results
The analysis found no evidence for cold wake suppression effects at the basin scale. Inter-arrival times followed exponential distributions (p > 0.05), and storms exposed to cold wakes showed no intensity reduction (exposed: 81.0 knots vs unexposed: 73.3 knots, p = 0.984). Results suggest climate oscillations dominate temporal patterns over localized ocean cooling effects.
Tropical Cyclone Cold Wake Analysis
Statistical testing of hurricane timing patterns and cold wake effects
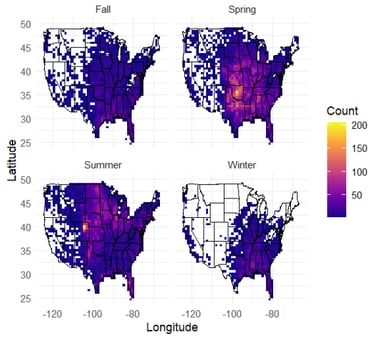
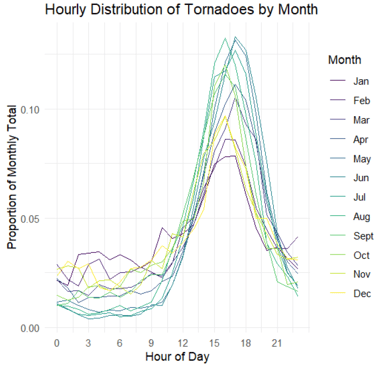
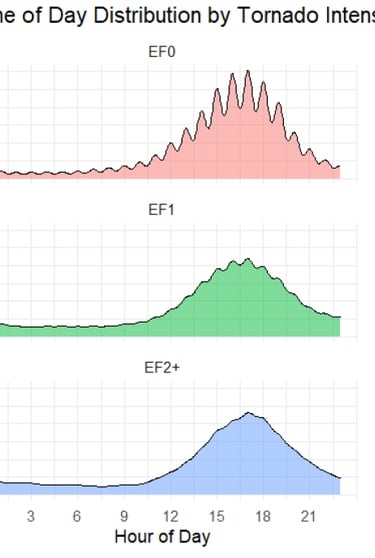
US Tornado Pattern Analysis
Comprehensive spatiotemporal analysis of 70,000+ tornado events across multiple dimensions
R • Spatial Statistics • GAM Models Kernel Density Estimation • Spatstat Diurnal Cycle Analysis
Goal
Tornadoes represent one of the most destructive natural phenomena in the United States, yet their spatiotemporal patterns are not fully understood. The goal was to conduct a comprehensive analysis of 70,456 tornado events to identify long-term trends, seasonal migrations, diurnal cycles, and spatial distributions of tornado activity.
Proposed Solution
I employed multiple statistical approaches including Generalized Additive Models (GAMs) for trend analysis, kernel density estimation with great-circle distance metrics for spatial patterns, and temporal analysis of diurnal cycles. The analysis incorporated spatial point pattern analysis, multitype K-functions, and comprehensive visualization techniques across 74 years of tornado data.
Outcomes
The analysis revealed systematic seasonal migration of tornado activity from Gulf Coast states in winter to Northern Plains in summer, with a pronounced diurnal peak at 5:00 PM (48% of tornadoes occur between 2-8 PM). Despite increased detection rates, tornado intensity distributions remained stable over time, and fatalities showed a significant downward trend due to improved warning systems.

Results
The Random Forest model achieved the best performance with an R² score of 0.816 and RMSE of $270,534 AUD, demonstrating strong predictive capability for housing prices. Feature engineering provided measurable improvements, with KNN showing the most significant gains (4.6% R² improvement) while maintaining robust model interpretability and validation.

Python • WebSockets • Asyncio • JWT Auth REST API • HTML/CSS/JS
Interested in talking markets, data, or building something new? I'm always happy to connect.
Contact
Let's connect and talk data science.
Phone
d.defreitas@wustl.edu
+1-314-646-9845
© 2025. All rights reserved.
MEETING LINK